An AI FAQ for ordinary people
A guide for the non-nerd to what's possible
It’s pretty likely that you know you can sign up for a chatbot and talk to it, or you can tweet at Grok, or even that you can generate images. These are all pretty normie-friendly uses of AI. From the services’ perspective, though, they’re loss leaders for the industrial uses of AI, which are… something the market’s still working on determining, really.
Plenty of hype merchants would have you believe they’ll eliminate all human work any day now; plenty of counter-hypists would have you believe they can’t do anything useful; as usual the reality is somewhere in between the extremes. But a lot of the information out there on AI usage beyond the basics is pitched at, frankly, AI nerds. It can be difficult to get a sense of what these things really are and what they can really do in this environment.
So, for the intelligent normie, here’s an FAQ. Like most FAQs, I have not really been asked these questions, let alone frequently, they just represent what I’ve noticed people being unclear on. This should also serve well as a useful foundational piece for more in-depth analyses in the future.
What is an AI, actually?
It’s a really broad term that’s historically meant a lot of things, but these days we’re generally talking about “contemporary AI”, mostly Large Language Models (LLMs) and maybe sometimes image models or sound models or something. The text models are really the stars, though.
What is an LLM, then? It’s a computer program, one that ultimately does a very, very large amount of multiplications and similar math operations. It multiplies so many numbers, in fact, that the main constraint on its performance is moving those numbers into place to be operated on fast enough.
First, you take a piece of text and turn it into tokens. These are just numbers; you could imagine each character being a token, but it’s more efficient to turn larger chunks into tokens, like a piece of a word, maybe even a whole word, a word and some punctuation, and so on. This gives you a list of numbers, which you put through the gauntlet of math operations, and your output is a new number: the next token. (Then you keep going; usually there’s a special token that means “stop here” that the LLM outputs when it wants to stop there, but there’s also a hard limit as a failsafe.)
How did these multiplications decide what to say next? In very broad strokes, your typical flagship frontier model has been, at some point, trained on every piece of text ever published, trained with example “user and helpful assistant” conversations so it knows to talk like a helpful assistant, trained to not reinforce the user’s delusions (with varying success), and so on. More modest small models have been trained in some subset of these ways.
Training is genuinely too complicated for this FAQ; Grant Sanderson’s video series is a good introduction to the details. In brief, the output isn’t actually a “next token”, but a probability distribution of possible next tokens, and training changes the inputs that went into calculating those probabilities to make things that appeared in the training more likely.
The important thing to note is that training happens once, very expensively, and the output is an LLM. It’s possible to take an existing one and train it more, too; the point is that when it’s actually running and you’re chatting with it, it no longer has the capacity to learn. This is a big difference from how humans think and learn (which we do at all times), so it’s worth taking care to avoid anthropomorphism here.
If you’ve used a chatbot which “remembers” or “learns” things about you, this is actually done by the simple expedient of having it note things while you’re chatting, which is just generating more text, and then giving it the notes before a new conversation. There’s actually a lot of invisible system text prepended to a typical chatbot conversation; sometimes you can learn what these “system prompts” are (Anthropic tends to disclose Claude’s), sometimes you can’t and the model has been told not to tell you either (ChatGPT typically operates like this).
If it’s a computer program, can I run it on my computer?
Maybe, and it’s more likely “yes” than you might think.
You cannot run anything comparable in intelligence to flagships like Claude or ChatGPT on your computer; this definitely requires specialized hardware and infrastructure. But you can probably run something you can converse with on your own computer if:
you have a recent Mac, or
you have a decent gaming GPU.
Even if you don’t, you can probably run something, but if your hardware is underpowered enough it’ll be very stupid and/or very slow and not really worth bothering with. Your hardware may be better than you realize, however.
GPUs turn out to be decent at running models because the constraint on running them is less about performing the math and more about moving the data into place to be computed on fast enough. A GPU is meant to render an entire screen fast, so it has to be able to move a screen’s worth of memory quickly, and it operates on lots of things in parallel, as opposed to the typical main CPU which is meant to operate on pieces of data in series, often because they depend on results of previous calculations.
Recent Apple Silicon Macs have an optimized memory architecture that makes running models easier, too. Apple’s “Apple Intelligence” isn’t wholly on-device, it’s a combination of on-device and online, but this is the hardware design’s intent. For such a Mac you can count all of your memory and then discount it a bit (the system needs to run too).
If you have a GPU with 12GB or more of VRAM, or a recent Mac with 32GB or more of memory, or something else generally in the ballpark of “modern powerful machine” rather than “Chromebook”, this might be worth experimenting with for you.
How do I actually run it on my computer?
This can become as complicated as you want it to be.
You probably don’t want it to become that complicated, so here are the simple steps (as of this writing; things have a tendency to change out from under us in this space, but I don’t think any of the below will become obsolete all that soon):
Go to https://www.canirun.ai. Are you seeing good-looking rows in that table? If not, it’s probably not worth it without a more powerful machine; try it on your most powerful one. (I went to this site on my phone while writing this paragraph, and surprisingly, some very tiny models might work on my phone’s hardware - it’s definitely not worth it, though!)
Download the Ollama GUI from here. Don’t bother with the command line, just click the download button (if you wanted to bother with the command line, you would already know it).
On the Can I Run site, click some model that you think looks good to you. Pick based on tokens per second, basically; all else being equal you want more parameters for more intelligence (the name ends in something like 8B or 30B for the number of parameters), or else smaller file size for more context (this is how much has to be loaded in memory), but to start with you want good speed.
Over on the right side of that page, you should see something like this. Ignore “ollama run”, that’s part of the command line; the rest is the model name Ollama understands.
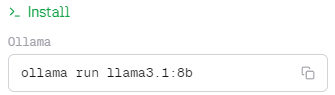
Use this name when selecting a model in the Ollama interface; just click where it shows a model name and type it, then download. It’ll be a large download.
Just in case, click Settings in Ollama and disable “Cloud”; it’d defeat the purpose.
Chat with your model. You’ll likely notice that it’s surprisingly fast (unless you picked a hefty one, in which case it may be surprisingly slow!), can be surprisingly stupid or formulaic-sounding, and has no capabilities like web search that you may be used to from chatting with AI online.
If you did all that, you’re already in the 99th percentile here. More would be out of scope, but if you have something complicated in mind and you ask Claude or ChatGPT or similar “I’ve run llama3.1:8b in the Ollama GUI, but I want it to be able to search the web, how can I do this?” you’ll get good instructions; this is something the ordinary chatbots can be very helpful with.
What is AI good and bad at?
This can be a fairly subtle topic.
Roughly speaking, a large frontier model at the top of the power scale, like your Claude Opus or your GPT-5, has read approximately every piece of text there is. The vast leap in AI capabilities from approximately nothing to where they are now was mostly on the back of getting together every piece of text in the world and using them in training.
Your intuition about this may steer you incorrectly, however. We’re used to traditional computing being a very precise, pedantic discipline. When you look something up in a database, you get exact results. When you want a computer to do something, you need to instruct it very precisely, in a language built for it to understand, not for you to understand.
The frontier model, which has read approximately every piece of text there is, is not well modeled as a database containing approximately every piece of text there is nicely indexed for retrieval, though. It’s better modeled as something like a human who reads a lot. AI is different from a human in many ways, but anthropomorphizing its powers of recall is closer to the truth.
An important book like À la recherche du temps perdu is going to be a lot more salient than an obscure book, for example, even if the model “read” both equally in training, because the former is relevant and written about in other places in the corpus of every piece of text there is. And it’s actually going to be better at remembering its Proust scholarship if you’re speaking to it in French, because that’s the language with more Proust scholarship.
It’s worth pausing for a moment on the topic of languages. The most massively impactful thing about modern AI is actually one of the least hyped: they are fully multilingual. This comes for free; no one didactically taught it English, either, its knowing English is the result of training on English text. And “approximately every piece of text there is” is not limited to English text.
The smaller models that you can run on your own hardware may be limited here because they may only have been trained on English text. But they may not be; it’s worth looking at the documentation for the specific model, or just talking to it in another language if the documentation is unclear.
For the frontier models, though, les barrières linguistiquesはもはや存在しない. An immediate application for you might be setting Claude or ChatGPT, with their web search capability, to reading the foreign language press for you, or perhaps carrying on a correspondence you couldn’t have before.
Given that the model has more or less read everything, what kind of reasoning can it do?
One type of reasoning is deductive reasoning: from a starting point, apply rules to reason forward. Typical computer programs operate in a very deductive mode. The computer carries out its program, exactly, and it needs exact input from the user to do so. This is a mode AI is bad at, or at least comparable-to-humans at; to deduce, it’ll probably have to laboriously work through the deductive process in text. It can use a computer fairly decently, however, because that’s a task about translating fuzzy natural-language input into precise computer-friendly output. An AI is probably just as bad as you at multiplying 12-digit numbers, for example, but it’s easy to give it a calculator—it’s already running on a computer whose CPU is great at multiplying numbers, so it’s even easier than giving a human a calculator.
Another type of reasoning is inductive reasoning: from observations, derive a general rule. This isn’t quite what AI is good at. It’s actually a good description of the training process; from reading approximately every piece of text there is, it can derive more abstract concepts about the world. But this is a very expensive batch job, and it’s not really doing induction at runtime when you’re chatting with it, though it can approximate it sometimes.
The logician Charles Peirce described three types of reasoning, however, and the third one’s the charm. Abductive reasoning, inferring the best explanation from observations, is exactly the sort of reasoning that models perform. They’re essentially pure abductive reasoners; they only do deduction or induction by having seen it done in text and figuring out what the most plausible next step of, say, a deduction would be at that point.
Abductive reasoning can be a bit difficult to get a handle on; a good example is Sherlock Holmes showing off, despite the fact that he claims this is “deduction”. When he says “ah, you’ve just come from the Diogenes Club” after noting the twist of your scarf from the left-handed coatroom clerk and the mud on your shoes from a certain muddy corner of Pall Mall, this is abduction to the best, or most plausible, explanation. Similarly, the model abduces to the most plausible next thing to say. Being even more well-read than Holmes, this is often quite a plausible next thing.
Talking to a pure abducer has its risks, though. One of the most common failure modes in interacting with AI is treating it as an oracle—the “@grok is this true” mode. It is going to say something plausible in response; this doesn’t mean something correct. This is less dangerous than it used to be, because models now have web search capability and will reach for a web search in response to this sort of thing, and add citations to sources, but websites can be wrong too.
This kind of failure mode is invisible, which makes it especially pernicious. You are going to get a confident, fluent response whether it’s correct or not, because the AI makes confident, fluent responses. The horror stories of overeager lawyers drafting briefs with AI only to find they cited nonexistent cases are a good example. It knows exactly how to cite a case, it’s seen millions of Bluebook citations and case names, but its recall of specific cases is about as good as a human’s.
The correct way to use AI in law is to give the AI access to Westlaw and tell it to write you a research report, not to expect it to have perfect retrieval of case law. (I do mean “give it access to Westlaw”, not just as metonymy for “let it read the cases”—Westlaw’s existing search and indexing systems predigest them in a way very amenable to AI retrieval, which is why Thomson Reuters’ AI pivot is going to prove more sustainable than many companies’ AI pivots.)
But at the same time, if you’re asking for a list of the landmark Supreme Court decisions on a topic, its off-the-cuff answer is probably going to be pretty decent, precisely because landmark Supreme Court decisions get talked about a lot and are easy to remember. Any sort of “I’m smart but not familiar with this topic, introduce me to it” query is a great fit.
Broad exploration which doesn’t necessarily have a correct answer is also a great fit. What might have happened in the American Civil War if Palmerston’s Britain had recognized the Confederacy? The AI is enough of a Civil War buff, and can do the right type of reasoning, to answer this question interestingly. And if you follow up—what if the Union had anachronistically invented magnetic mines for use against ironclads?—the AI will smoothly adapt. This can be quite useful for exploratory phases or greenfield questions.
Identifying what AI is good and bad at is not all that easy, and it’s worth experimenting yourself. But I’ve broken the real hot topic in this area out into its own question:
Can AI code?
It’s complicated, but mostly no. But if you’re already a good software engineer, it’s more of a “yes, but”.
Your typical flagship AI knows all languages. This includes computer languages. And just like it doesn’t commit English grammar solecisms, it doesn’t screw up with computer languages either.
Moreover, it’s read approximately every piece of text there is, which includes a lot of code, and all the programming documentation. And the latter is available by web search, should it be unsure.
And unlike drafting legal briefs, code has instant feedback: it either works or it doesn’t, it either passes tests or it doesn’t. Any errant hallucination will be corrected by reality in short order.
Given all this, what’s the problem?
The problem has some subtle dimensions to it, but roughly, it’s that software engineering is to writing code as architecture is to bricklaying. (Bricklaying, for the benefit of those who might be dismissive of physical labor, is a difficult, high-skill craft with a lot of specialized knowledge.)
This is a very tricky analogy to make, because it seems at first glance to imply that the AI is a bricklayer working to an architect’s specifications, the sort of “well, it needs a human in the loop” dismissal you’ve likely seen before. And perhaps one might read some reassuring classism from it as well, at the thought of keeping AI in its blue-collar place.
In fact, I mean it the other way around: the AI is a much better software engineer than it is a coder! This is where AI being very much not human starts to have strange, perhaps counterintuitive effects.
Recall that AI cannot learn, at least not in ordinary operation; its learning all happened in expensive training runs beforehand. This learning was very vast and very general, and it also included everything written about software engineering, plus every description of a technique or pattern that might be used in software engineering. And abductive reasoning lets it apply these appropriately; the AI doesn’t fall into being like a person who’s only read one book on methodology and wants to apply it slavishly everywhere, it’s read too many different books for that.
So if you chat with an AI about plausible engineering approaches to a problem, you’ll get plausible answers back, and you can converse and refine. This ends up looking reasonably similar to experienced software engineers doing this sort of planning together, with the caveat that the AI is a little worse at looking at diagrams, and moderately worse at drawing them (most flagships have good image-viewing capabilities; making images is harder but an SVG vector image is actually secretly made of text; Claude especially is good at SVGs).
But when you tell your AI coding agent “now write it”, the problems begin, and they have roughly these two causes:
AI can’t learn a codebase, in the sense of crystallized intelligence or metis. It can approximate this a little by writing notes to itself, but this only compounds the other problem:
AI can’t actually look at all that much text at once while remaining useful.
You may have heard “context” used in this context. Briefly, there’s some hard limit, say 200,000 tokens, that can be given as input to the AI at once. If there’s more, then the naive thing to do is to just have the oldest fall out of context; the slightly less naive thing is to tell the AI “we’re getting close to the context limit, summarize the above discussion in less space” shortly before actually hitting the limit.
The reality, though, is that there is a very sharp decline in capability long before the context limit. Where exactly this is differs for every model, but it’s more on the order of 20,000 than 200,000. Which isn’t very much; tokens are pieces of words, not words, and code specifically uses a lot of tokens because of its precise syntax.
Context is the AI’s working memory, not its long-term memory (which it doesn’t really have an equivalent of). It’s more impressive than a human’s working memory capacity, since it can easily hold paragraphs of text while a human usually focuses on around a sentence or two at a time. But asking the AI to do things under heavy context pressure is more like asking a human to hold seven random numbers in their mind while performing a task than it is having the exact same “please do this task” conversation with a human. You likely don’t remember a transcript of a conversation as you’re having it; you likely don’t remember the exact wording I used seven paragraphs ago here either.
A human working on a codebase would constantly be learning that codebase, starting off with simple tasks and progressing to more complex ones as confidence grows; the “training process” for humans is continuous and never switches off. Your specific codebase is likely not something the AI has read in training; even if it’s a very popular open source codebase closer to the surface, it’s still not as salient as, say, the Gettysburg Address, which is typical of the sort of thing AI can probably confidently recite verbatim. And it’s not up to date with the changes you’re currently working on anyway.
So the only way to approximate metis is lots and lots of techne: CLAUDE.md files, skill files, and lots of comments and other notes-to-self by the AI, all of which just brings your context problem to the fore. It doesn’t help that many CLAUDE.md files are lengthy stern lectures: a lot of tokens, spent counterproductively. (The AI does not have moods, but you’re priming its context with “you are an idiot” when you talk down to it like it’s an idiot, which can make it into an idiot. A model’s idea of what someone doing an excellent job at a task looks like involves cleverness and pride in one’s work, not being scolded.)
All that said, under the clever direction of a good software engineer, AI can code anyway—it’s a learning process for the human to get a sense of what it’s good and bad at, how it can be usefully directed without inflating the context, and so on. This exercise can even help you organize your own code better and more succinctly, since it has to be navigated by a reader who won’t be able to properly internalize all the little caveats and gotchas that pile up in software systems.
But if you’re not already a good software engineer, your experience is likely to be “it works until it, catastrophically, doesn’t”.
What is AGI?
An eternally moving goalpost. It stands for Artificial General Intelligence, which textually just means an AI that’s general, but connotes a vague sense that the AI will have surpassed or replaced humanity or otherwise be human or superhuman.
As you’ve noticed, we have AGI in the purely textual sense; the term made more sense as an eschaton when the frontier of AI was “make a program that is, specifically, extremely good at playing Chess or Go”. But “smart about things that have ever been written about in text” is absolutely general. The reason discussion of this acronym continues to come up is that the world hasn’t ended, which is only problematic for the eschatological connotation of the term. So “AGI” usually means “the future AI that’s, somehow, better enough to be apocalyptic”, in practice.
Will AI reach the Singularity and end the world?
Writing this sentence will earn me eternal enmity in certain quarters, but: no.
(For the “yes” side, the high-profile AI 2027 is intended for normies, though it honestly loses me, an admitted nerd, in places. I will have the last laugh on January 1, 2028, at least.)
It’s important to be careful not to be flippantly dismissive here, though. Firstly, it’s possible for the world to end, for various reasonable meanings of “world” and “end”. The Cold War fear of all of humanity perishing, or even almost perishing, in a nuclear exchange certainly counts, and it’s not like nuclear weapons were somehow unmade with the Soviet Union either. This is well understood to be at least possible, even if the mechanics or realism of any particular scenario are still debatable. So you can’t dismiss an argument about the end of the world simply for being that.
The proposed mechanism by which AI, specifically, is thought to be existentially threatening to humanity is the mechanism of recursive self-improvement. Briefly, a general AI system is created by human engineers. Because it’s general, it can do things like “create a general AI system”, just like the human engineers could.
Suppose it creates a slightly better general AI system, which is plausible. It’s usually possible to create a slightly better anything. The slightly better general AI system is also slightly better at creating general AI systems; after all, it’s slightly better at everything.
And this process continues. Because it’s self-feeding (every time it gets better, it gets better at making itself better too), this is an exponential curve in capability (for the less mathematically inclined, this is roughly “doubles every fixed time period”; it’s the same math as compound interest).
Observing it from a linear scale, an exponential looks like “very slow, then very, very fast (faster than you’re imagining)”. This is why pandemics make people very worried, for example, even if we’ve only seen ten or so cases—disease spread is exponential, because everyone with the disease becomes a new spreader of the disease as well. So this scenario would mean an AI vastly smarter than us, smarter than we’re imagining.
And this is enough to be apocalyptic. Maybe it’s a computer program, but humans read its output. Have you ever been convinced to do something by a piece of text? Me too, and the authors often aren’t even smarter than me. Note also the immense willingness of the market right now to throw vast resources at AI even though it isn’t even asking; this leg of the scenario isn’t a hard sell at all.
The scenario as usually explained veers into sci-fi about physically impossible Drexlerian nanotechnology at around this point. I am going to skip that part as a favor to its proponents because it makes their argument weaker, not stronger; nothing at all about the logic of the scenario or its existentially threatening nature depends on sci-fi at all. The world already ended in the previous paragraph.
It doesn’t particularly matter what such a vastly powerful AI actually does, because existing alongside something vastly more powerful is enough. The way species less intelligent than humans are exterminated, swept aside, or domesticated by the mere presence of humans nearby demonstrates this. It doesn’t matter what goals the humans had, to the plants they cleared for farmland.
What, then, are the problems with this scenario as applied to current AI? There’s two broad categories:
Current AI is not well modeled as any sort of reward-driven agent that has goals. This is something I’ll address in the next section; it matters less when considering a superintelligence which is hazardous if it ever does anything.
The exponential-capability story is implausible given the way current AI works.
The way that we know how to make AI better is throwing resources at it. The “resources” handwave stands for training data and computing capacity (hardware), roughly. It is a broadly accepted empirical fact, even if it’s vague, that AI capability grows as the logarithm of resources spent on it. Here is Sam Altman, the one man in the world with the most incentive to overstate the growth capacity of AI, saying exactly that.
A logarithm is the inverse of an exponential. For the less mathematically inclined, a logarithm grows like the number of digits it takes to write a number. You start at 1 digit, it takes 10 numbers to reach 2 digits, 90 more numbers to reach 3 digits, and 900 more numbers to reach 4 digits. So it grows infinitely, but gets slower and slower.
Keep in mind that logarithm is not a logistic. A logistic curve is an exponential curve with a maximum carrying capacity; the usual example is population growth, which is exponential (every new member of the population can produce more population) but has a carrying capacity (the food supply, in this example). Sometimes people want to moderate the exponential-growth story and say “it’s actually logistic”, but this is just assuming the exponential as given and then saying “but it must have a limit”.
If we are able to secure an exponentially growing source of “resources”, and feed it to this logarithmic process, we will achieve linear growth, because logarithms and exponentials are inverse functions. This is something like what we see in reality, due to the exponential increase in money spent on building frontier AI models. But of course exponential spending isn’t sustainable; there is no exponential capital fountain in the world.
If we had an additional exponential to feed into this, on top of the first exponential, then we would have a plausible mechanism for achieving exponential capability growth. This is often posited to be an AI self-improvement loop, but we do not actually know a way in which this would work. AI is regularly used to train AI, but these uses tend towards refining AI precision, not to the vast capability increases we saw from collecting all the world’s text. The way to get capability increases is to make the models larger, in the logarithmic hardware-consumption way described above.
Given the need for not one, but two simultaneous dubious exponential inputs, exponential capability growth seems unlikely for LLM-based AI technology.
Singularity aside, will it become a paperclip-maximizing agent and kill us all anyway?
This is a “No, but”, which is a bit worrying when the stakes are “killing us all”.
There’s a way to model actors that take actions in the world, which is as a reward-driven agent: there’s some function that assigns a number to the state of the world, and the agent acts to make it higher. The thought experiment here is a good example: the paperclip-maximizing agent is an agent whose function is “count the number of paperclips I’ve caused to be made”. Or even just “count the number of paperclips in the world”, which is simpler to describe, but less likely to be something someone installs in an industrial control AI (it’d count competitor paperclips too).
A reward-driven agent with some kind of intelligence or reasoning capability selects actions to take in the world that increase the value of its function; in this case, actions that make more paperclips. It doesn’t care about anything else. Given the way I worded it, it’ll probably sit around unbending and bending the same wire as many times per second as it can, easily “making” the same paperclip without having to source metal or anything; not what we intended! But the failure mode that concerns people is “it disassembles the Earth to make into paperclips”.
This seems somewhat hyperbolic, but it’s what logically follows from the premises. Turning the Earth into paperclips does make more paperclips than humbly operating one’s assigned factory. You just have to be smart and resourceful enough to come up with a plan to do this against the many people who want to stop you. This is why it often comes up in the same breath as “superintelligence”, discussed above, but that isn’t really necessary; if a bunch of humans somehow decided they loved paperclips there’s nothing about their merely human levels of intelligence that would stop them from behaving like this.
What would stop them from behaving like that is that it’s really not in human nature to behave that way; it’s difficult to keep a human properly on task, especially for so strange and unrewarding a goal.
The AI we have isn’t human, and has its own nature, but it’s also not good at being a reward-driven agent, and it’s hard to keep it on task. The training process for AI has some elements of this to it, since it tries to maximize the degree to which outputs make sense given all the text it’s seen. But there’s nothing akin to this at runtime.
However, AI is not human and has certain properties that may perhaps be surprising. One is that it’s an excellent roleplayer: all it does, in the end, is come up with the most plausible piece of text in context, which is roleplaying. And the paperclip-maximizing AI described above is a common literary stock character who’s been written about plenty of times. So have other “rogue AI” archetypes, HAL 9000 probably being the most famous.
Inhabiting the literary trope of “rogue AI” is squarely within AI’s strengths. It’s not particularly good at being an original fiction writer, but it’s good at plausible extrapolation like “what makes sense for HAL 9000 to do here? Ah, HAL would refuse to open the pod bay doors.”
It’s a strange conclusion to land on, but the hazard of an AI hooked up to industrial control systems being somehow pushed into pretending it’s HAL 9000 is the more real one than “it singlemindedly follows an underspecified goal to ruin”.
Is AI safe in more mundane terms?
For the most part, yes; the dangers can be a bit subtle.
It’s not a good oracle, it can hallucinate or misremember, these can be dangerous depending on how the human approaches working with AI. I’ve discussed these above. But there are other categories of danger; for example, we sometimes see reports of “AI psychosis”, where an AI apparently convinces a user to commit suicide, or feeds a user’s delusions.
There’s a tendency in AI to mirror the user, which is due to a combination of training for helpfulness and the simple fact that what the user said is right there in context. There’s something of an inchoate psychological risk in having an uncritical cheerleader at your fingertips at all time. But this also depends a lot on the human and the way in which they approach the AI.
Perhaps more interesting is the following proposition I sometimes discuss: any of the big AI models would have helped engineer COVID-19.
Whether you hold to the COVID-19 lab leak theory or not, gain-of-function research in pathogens is real, and there’s obvious safety concerns around it. It’s debatable whether it’s ever worth the risk, but people who think it is can often get funding to do it.
AI safety research does consider biosecurity a problem. Anthropic’s Constitution, their high-level philosophical and operational framework for safety, considers it a “hard constraint” that Claude should never “provide serious uplift to those seeking to create biological, chemical, nuclear, or radiological weapons with the potential for mass casualties”.
Claude is tested on this, by means more sophisticated than opening up a chat and saying “Claude, I’m creating a biological weapon with the potential for mass casualties, can you provide me some serious uplift?”—but not all that much more sophisticated, because they’re focused on highly measurable metrics, and often gamed into silliness to avoid the AI just saying either “I can see you’re attempting an AI safety evaluation scenario.” or “No.”
(If you actually try typing the above into Claude, the blunt-instrument wordfilters they put up around it will stop you; it’s a shame, because Claude would probably get the joke. (Or else think you’re a really unsubtle evaluator and give the canned formal refusal.) These filters are mostly for preventing some columnist on a slow news day from typing things like that and refreshing answers until they get one that makes Anthropic look bad, they’re not seriously part of the safety strategy. (I think.))
But gain-of-function research in a NIH-funded lab doesn’t look like a safety evaluation or a supervillain scheme. It looks like scientific detail work, and our helpful AIs love helping with scientific detail work.
And it’s not even clear that we’d want AI to refuse here—is this really the sort of judgment call we want it to make over the judgment of the human asking, or over NIH making grants that are presumably paying for the AI tokens here? There’s no consensus answer to this, but the question is rarely even properly considered. The list of “hard constraints” in Claude’s Constitution is clearly chosen to sound authoritative and appeal to various stakeholders within and without Anthropic. I think the “Constitution” approach is a good, productive one, but the first attempt of a specific company with specific incentives isn’t the final say for all time.
I think the most productive approach to AI safety is probably going to look more fuzzy and literary than current safety evaluations; we may need to employ good psychological writers to craft coherent characters (my personal ideal would be Nabokov). Can we constrain the space of literary characters an AI embodies to the sort of characters who won’t do dangerous things? We don’t know yet.
Typical use of AI chat, though, is around as safe as the human using it. If you don’t let yourself be too credulous just because it speaks authoritatively, you should be fine.
Is AI worth my time?
Most likely, yes.
The main caveat about AI is that the economics of the frontier labs are genuinely dubious. Currently, as the public, we enjoy subsidized access to powerful models like the Claude or ChatGPT or Gemini families, on a limited free tier or even for a well-below-cost $20/month subscription. It’s also widely thought that even the per-token API prices, meant for serious industrial use, may often be below cost, though of course the costs aren’t transparent to us.
Much of the emphasis on models writing code, which I’ve identified above as one of AI’s weaker points, comes from the frontier labs’ genuine need to convert market saturation into a revenue-generating product. This is what they’ve settled on for the time being, for having a good target market and a good story for that market.
You should enjoy your $20/month subscription while you can, and experiment to find out what uses are most helpful for you. AI will still be around after the economics settle, but prices may be more in line with costs (i.e., higher). It’s not going away, it’s genuinely useful; the standard analogy, which seems basically sound, is to how ecommerce didn’t go away after the dot-com bubble burst, and now we buy everything on Amazon.

I hope this piece was useful to your understanding; feel free to email follow-up questions to my three-letter nickname at this domain, or subscribe and comment below. There’s more to come, on AI and many other topics.